随着大数据时代的到来,数据已经成为企业的核心资产之一。在过去几十年间,数据技术也随之不断演进,从早期的数据仓库到近年来热门的数据中台,再到正在快速发展的数据飞轮概念,每一步都是技术革新的体现。
一、数据仓库:集中化的数据管理起点
1. 数据仓库的诞生
数据仓库(Data Warehouse,简称DW)可以追溯到20世纪80年代末。彼时,企业内部存在多个业务系统,数据分散,难以进行统一分析与决策。于是,数据仓库应运而生,旨在将这些分散的业务数据进行集中化存储和管理,主要用于业务报表和决策支持。
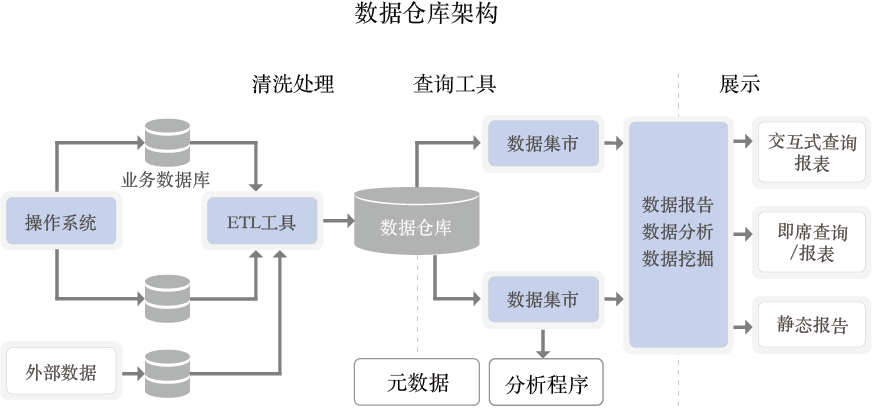
2. 数据仓库的核心理念
数据仓库的核心理念是将来自不同业务系统的数据进行整合、清洗、转换,并存储在一个统一的环境中。这种集中化管理方式帮助企业能够轻松地进行历史数据查询、分析报表等,支持业务决策。早期的数据仓库依赖于传统的关系型数据库(如Oracle、SQL Server等),并且数据的加载通常是批量处理的。
示例:数据仓库中的ETL流程
-- 从业务系统提取数据
SELECT * FROM sales_db.orders;
-- 转换和清洗数据
INSERT INTO data_warehouse.clean_orders
SELECT order_id, customer_id, product_id, total_amount
FROM sales_db.orders
WHERE total_amount > 0;
-- 加载到数据仓库
INSERT INTO data_warehouse.fact_orders
SELECT * FROM data_warehouse.clean_orders;上面代码展示了一个典型的ETL(Extract, Transform, Load)流程,将业务系统中的销售订单数据提取、清洗并加载到数据仓库的事实表中。数据仓库通过这种方式实现了企业级数据的统一管理。
3. 数据仓库的局限性
虽然数据仓库在支持历史数据分析方面表现出色,但它并非没有局限性。随着企业数据量的爆炸性增长,传统的数据仓库在扩展性和实时性方面遇到了挑战:
- 扩展性差:传统数据仓库架构较为封闭,难以快速扩展。
- 实时性不足:批量数据加载导致数据延迟,无法满足实时分析需求。
二、数据中台:从集中式到分布式的数据服务
1. 数据中台的崛起
为了应对数据仓库的局限性,尤其是在企业数字化转型背景下,数据中台(Data Middle Platform)这一概念开始受到关注。数据中台的核心思想是打破数据仓库的“孤岛效应”,通过数据服务化和分布式计算能力,提供一个可以灵活调用的“数据基础设施”。
2. 数据中台的核心特征
与数据仓库不同,数据中台更关注数据的实时性、共享性和服务化。它不仅仅是一个存储和分析工具,更是企业的数据资产管理平台,能够支持数据的高效流转与复用。
示例:数据中台中的实时数据流处理
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
# 使用Spark处理实时数据流
spark = SparkSession.builder.appName("DataPlatform").getOrCreate()
# 从Kafka中读取实时数据
orders_df = spark.readStream.format("kafka").option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "order_topic").load()
# 进行实时数据计算
order_count_by_window = orders_df \
.groupBy(window(orders_df.timestamp, "10 minutes"), orders_df.product_id) \
.count()
# 将结果输出到数据中台
query = order_count_by_window.writeStream.format("console").start()
query.awaitTermination()这个例子展示了如何使用Spark Streaming处理实时数据流,并在窗口化的基础上计算每10分钟内每个产品的订单量。这种实时数据流处理正是数据中台区别于传统数据仓库的重要特性之一。
3. 数据中台如何超越数据仓库
- 实时性增强:数据中台通过实时计算引擎(如Flink、Kafka、Spark等)实现了数据的实时处理,满足了企业对即时数据的需求。
- 数据服务化:数据不再局限于某个特定部门或系统,而是通过API接口等方式进行统一服务化,其他业务系统可以随时调用。
- 数据资产化管理:数据中台不仅整合数据,还帮助企业管理数据资产,并通过元数据管理、数据血缘分析等手段提升数据治理能力。
三、数据飞轮:从业务反哺到数据循环
1. 数据飞轮的概念
数据飞轮(Data Flywheel)是近年来在大数据领域的一个热门话题,它基于亚马逊提出的“飞轮效应”理论,强调数据与业务间的循环交互。不同于数据仓库和数据中台,数据飞轮更加强调数据反馈对业务增长的推动作用。
数据飞轮的关键在于数据的循环使用,即通过数据驱动业务优化,业务优化又产生更多的数据,进一步推动数据的迭代升级,形成一个持续增长的“飞轮效应”。
2. 数据飞轮的运作机制
- 数据收集与分析:通过数据中台等基础设施收集并分析业务数据,挖掘出新的业务机会或优化方向。
- 智能决策与执行:将分析结果通过AI算法或数据模型反哺到业务系统中,驱动产品或运营决策的调整。
- 数据的再生产:随着业务调整,产生新的数据,反馈给数据系统,进行进一步分析,形成闭环。
示例:数据飞轮中的机器学习模型
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 模拟从数据中台中获取用户行为数据
data = data_platform.fetch("user_behavior_data")
# 拆分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data.features, data.labels, test_size=0.2)
# 训练模型
model = RandomForestClassifier()
model.fit(X_train, y_train)
# 预测用户行为并输出结果用于业务优化
predictions = model.predict(X_test)通过机器学习模型对用户行为进行预测,输出结果后可以应用于业务场景中,如个性化推荐、产品优化等,从而推动业务的增长。这是数据飞轮效应的一个典型表现:数据推动业务优化,业务优化产生更多的数据,进一步完善模型和决策。
3. 数据飞轮与数据中台的区别
虽然数据飞轮与数据中台在某种程度上是递进关系,但它们之间仍然存在一些本质区别:
- 反馈循环:数据飞轮强调的是数据的闭环使用,而数据中台更多关注的是如何高效整合和管理数据。
- 智能决策:数据飞轮通常依赖于AI、机器学习等技术来推动业务优化,而数据中台则主要提供基础设施和服务支持。
四、数据飞轮是数据中台的高级形态吗?
数据飞轮可以看作是数据中台的高阶形态,但它们并不是同一个概念。数据中台更侧重于数据的管理和服务,而数据飞轮则是在此基础上,进一步实现数据与业务的深度结合,通过数据反哺业务,不断迭代优化。
对于企业而言,数据技术的演变从数据仓库到数据中台,再到如今的数据飞轮,每一步都是数据架构和管理能力的升级。而随着AI和机器学习等技术的进一步发展,数据飞轮所带来的业务增长和创新潜力将会更加巨大。